


我们对生成式 AI (Generative AI) 的态度,始终建立在对人类创造力的深切尊重之上。技术的设计初衷是为创作者赋能,而非取代他们,并坚持以创作者为核心、负责任的创新理念。
Veras 和 Chaos AI Enhancer 使用的是 Stable Diffusion 模型,该模型以 LAION-5B 数据集进行训练。LAION-5B 是一个公开的数据集,该数据集由 Common Crawl 抓取的网页图像与文字说明构成。对于其他模型,我们仅使用开源且适用于商业用途的数据集,或已经获得正式授权的数据集。
在 Veras 和 Glyph 中,仅当您主动选择共享时,系统才会收集匿名渲染与使用数据。您可以在初始设置中关闭该功能,或通过我们的 IT 配置指南全局关闭 Veras 与 Glyph 的数据共享。
对于 AI Enhancer,匿名的输入与输出图像仅用于质量保障(QA)与诊断分析。
只要您的合同允许,并且您遵守所使用的第三方模型或资产的相关规定,您的输出内容完全归您所有。
Chaos 不会对您的任何输出主张所有权。
我们的 AI 工具旨在鼓励并强化人类的创作主导地位。它们通过使用您的输入数据,并让您自主选择种子值、提示词、控制参数和输出结果,从而优化创作流程。同时,系统始终保留必要的人类创作成分要素,并确保符合美国版权法对著作权归属的要求。
根据美国版权局(U.S. Copyright Office)的规定,当人类对图像进行创作贡献或具有实质性编辑时,AI 生成内容可以获得版权保护: 阅读官方指南。Veras 在渲染过程中使用您的 3D 模型和相机视角作为视觉基础(即“底层素材”),这意味着输出图像是基于您创作内容之上。同时,您在使用过程中还参与了提示词编写、种子设置、渲染选择等环节,这一过程体现了人机共创。因此,Veras 的使用过程中所包含的人类参与,明确符合美国版权局关于可版权内容的要求。
在欧盟,判断标准则更侧重于作品本身的原创性。不同国家可能对“足够的人类创作参与”或“独创性”的认定存在细微差异,因此,尽管“人类参与”仍是核心因素,但各国在法律适用上可能存在细微差别。
我们可以明确向您保证:Chaos 不会主张您通过 Veras 所生成输出内容的所有权。但出于产品运营与功能改进的目的,我们可能会保留部分有限的使用权。此外,我们可能会对产品、服务或内容的使用施加一些限制,例如:禁止违反适用法律的使用或涉及将我们专有内容“实体化”的行为。相关详细条款请参阅我们的《许可与服务协议》。
您对输出内容所拥有的权利,还取决于多种因素,特别是图像生成的具体背景(例如是否为独立创作、雇佣工作成果或客户委托项目),以及所使用模型或资产中是否包含第三方素材或权益等内容。
Veras 基于 Stable Diffusion 模型构建,该模型是在 LAION dataset 数据集上训练而成。LAION 是一个大规模、公开可获取的图文配对数据集,内容来源于互联网。
不是的。Veras 生成的输出并非对某一训练图像的复制,而是基于您提供的 3D 设计结构和文本提示,生成全新的内容。只要输入是您的原创,输出也完全归您所有。
Veras 仅将渲染所需的核心数据(如相机视角与几何快照)发送至云端进行处理。
归您所有。AI Enhancer 只是对您原始渲染图进行视觉增强处理,并不会引入新的内容或改变您的设计意图,因此其知识产权完全归您所有。
AI Enhancer 基于 Stable Diffusion 模型运行,该模型以 LAION dataset 进行训练。LAION 是一个大规模、公开可用的图文配对数据集,数据来源于互联网。同时,AI Enhancer 还结合了开源的图像处理技术,如降噪与细节增强等。该模型未使用任何用户生成内容进行训练,也不会引入任何外部图像。
我们在美国存储输入与输出图像,仅用于质量监控与诊断目的,符合最终用户许可协议(EULA)的规定。这些数据不会被用于模型训练,也没有任何训练计划。
归您所有。Glyph 完全在您的 BIM 环境中运行,其输出内容(如视图、图纸、标注和尺寸)均基于您的模型生成。生成结果由您的提示与输入驱动,所有输出均保留在您的项目中,始终处于您的控制之下。
Glyph Copilot 基于 OpenAI 的 ChatGPT(GPT-4),用于辅助执行 Glyph 的任务与流程。该大型语言模型(LLM)是在广泛的公开互联网数据上训练而成,不包含任何客户内容。
Glyph 不会使用您的数据对模型进行再训练或微调。
目前不会。但根据《最终用户许可协议》(EULA),我们保留未来可能使用的权利。在首次启动应用程序时,可以看到两个选项框,您可以将其关闭,以禁止匿名收集图像、提示词以及应用使用数据。
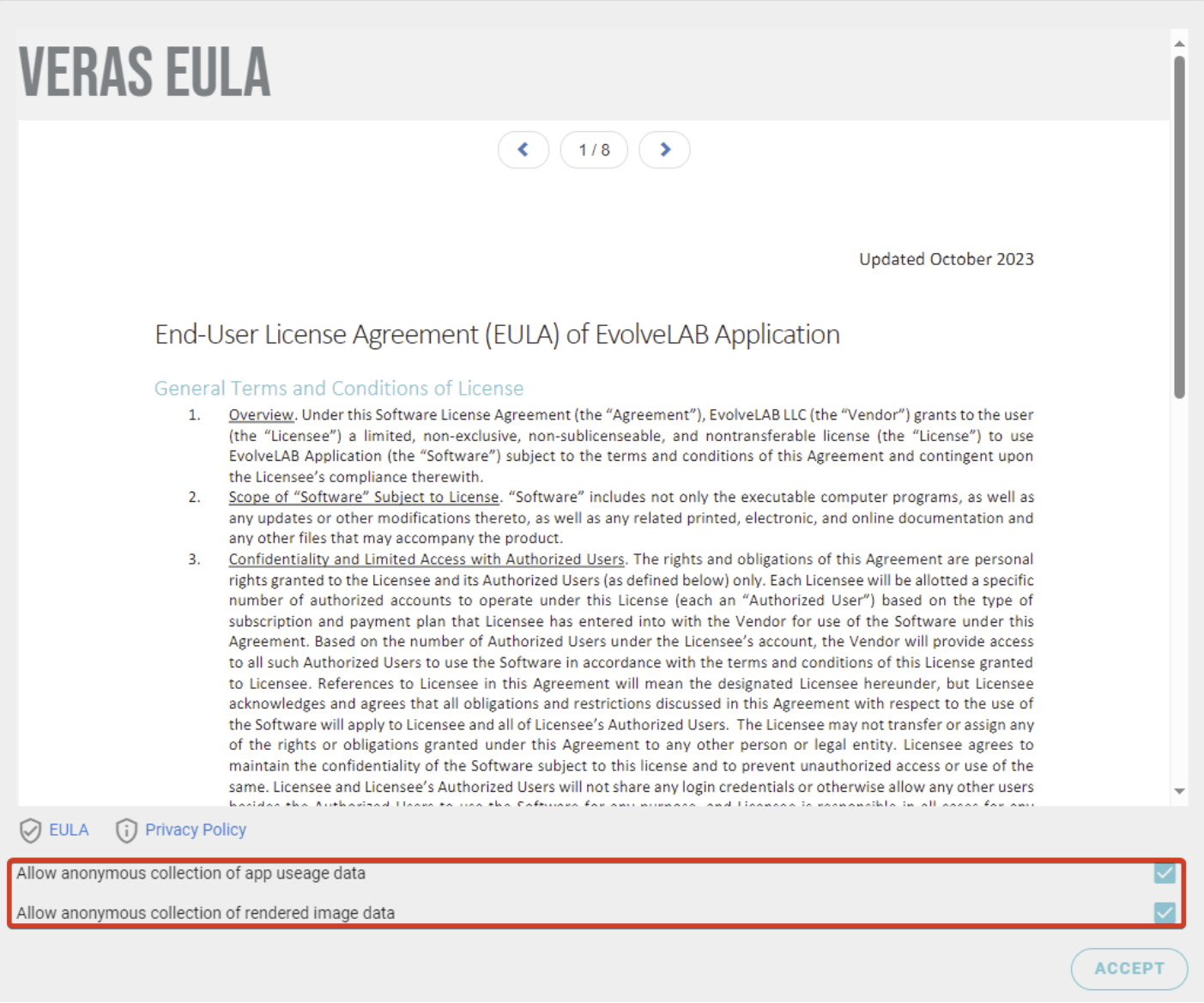
若要在全局范围内关闭此功能,IT 专业人员可按照以下说明操作:https://forum.evolvelab.io/t/installing-veras-msi-configurations-remote-deployment-for-it-managers/4717
